LLaVA: Large Language and Vision Assistant
2024-04-10Overview
LLaVA is a large multimodal model that connects a vision encoder with a language model, aiming for general-purpose visual and language understanding. This type of model can understand and generate text, as well as analyze and interpret visual content such as images and videos. By combining these two domains, LLaVA can perform a wide range of tasks, including:
- Image Captioning: Generating descriptive text for images.
- Visual Question Answering (VQA): Answering questions about the content of images.
- Multimodal Dialogues: Engaging in conversations that involve both text and images.
- Content Moderation: Identifying and filtering inappropriate content in images and text.
- Augmented Reality (AR) Applications: Enhancing real-world environments with interactive visual and textual information.
LLaVA leverages large-scale datasets and sophisticated deep learning architectures to achieve high accuracy and versatility in these tasks. Its ability to understand and generate both language and visual information makes it particularly useful in applications such as virtual assistants, automated content creation, and intelligent search engines.
LLaVA is open-source on GitHub. It is trained end-to-end using instruction-tuning with language-only GPT-4 generated multimodal instruction-following data. It demonstrates impressive multimodal chat abilities and achieves a significant relative score compared to GPT-4 on a synthetic multimodal instruction-following dataset.
Visual chat
It is very cool that we can chat about the image, as shown in the screenshow below (from https://llava.hliu.cc/).
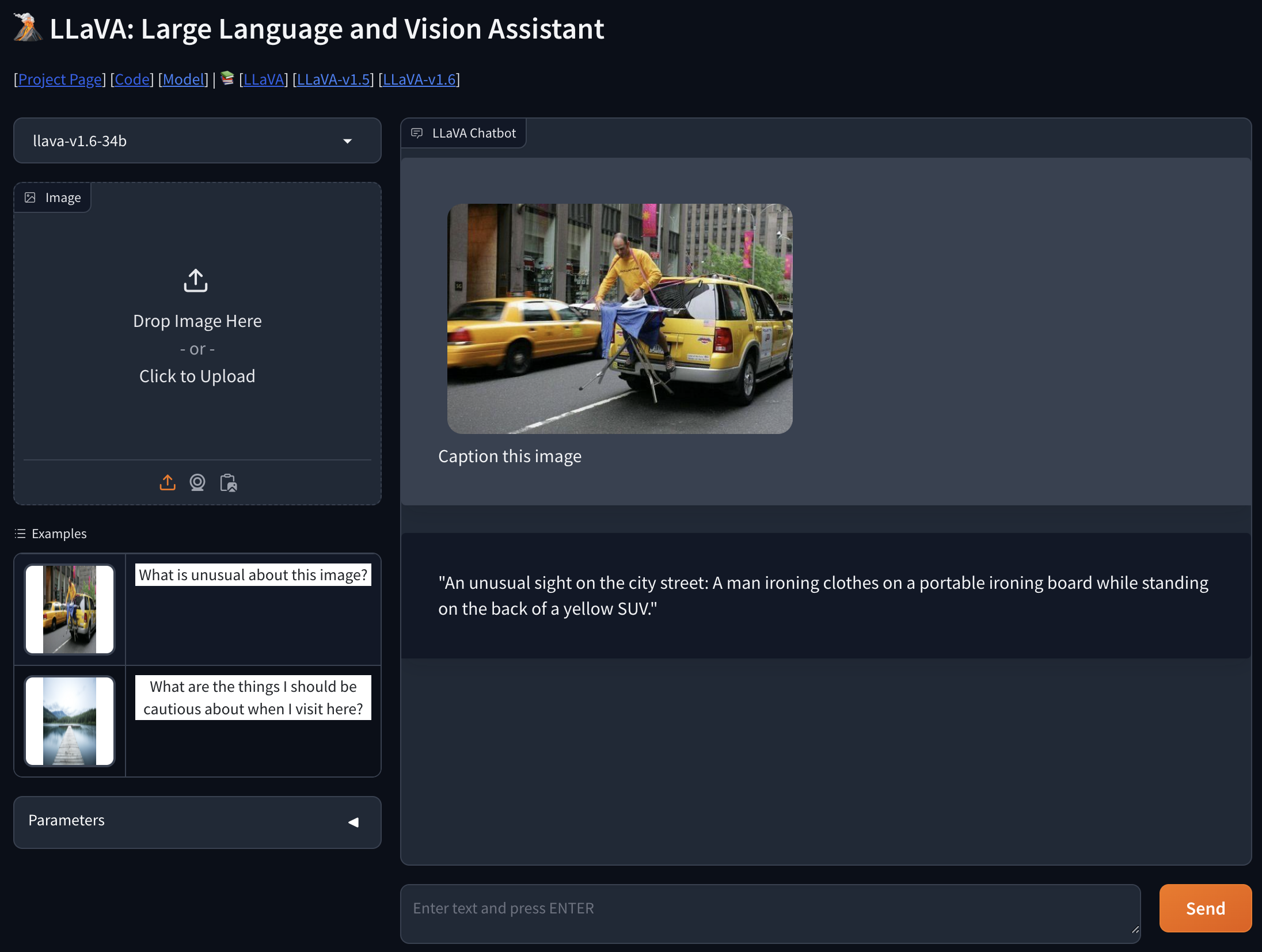
Image Captioning
Caption an image with LLaVA is simple and easy. We can just provide an image and prompt LLaVA to caption it. Let's try it out with the llava-13b model hosted on replicate.com.
# Set the API token to environment variable, replace the placeholder with your own token
$ export REPLICATE_API_TOKEN=**********************************
# Install replicate
$ pip install replicate
Next we can run yorickvp/llava-13b using Replicate API.
import replicate
input = {
"image": "https://replicate.delivery/pbxt/KRULC43USWlEx4ZNkXltJqvYaHpEx2uJ4IyUQPRPwYb8SzPf/view.jpg",
"prompt": "Caption the image for my Instagram post."
}
for event in replicate.stream(
"yorickvp/llava-13b:80537f9eead1a5bfa72d5ac6ea6414379be41d4d4f6679fd776e9535d1eb58bb",
input=input
):
print(event, end="")
#=> "Yes, "
Output: "A serene scene of a dock extending out into a large lake, surrounded by a forest. The dock is empty, and the water is calm, making it a perfect spot for relaxation and reflection."